
Ruby Caches - Rails Cache Workflows

A series of posts will explore and detail some of the current Rails caching code. This post explores the steps and type of work involved in caching.
These posts attempts to explain in a bit more details, but please do read the official Rails Caching Guide docs, which are also very good.
Rails Cache Posts:
- Rails Cache Initialization
- Rails Cache Comparisons
- Rails Cache Workflows
Rails Cache Workflows
What happens as part of caching… Like most software, it isn’t magic. This post will break things down a bit so we can talk about and dig in deeper on some of the specifics. I mostly work with and cache about low-level usage of Rails.cache while much of the Rails Caching Guide focuses on view layer caching. My experience has always required more complex caching at the data layer, not just a lazily deferred view layer. Rails view layer caching is built on these same primitives, so when we talk about low-level caching, we mean the Active Support Cache API for interacting with the cache directly. While it supports many things, we are going to dig in on the most commonly used features:
-
Rails.cache.read: this method gets data from the cache -
Rails.cache.write: this method puts data in the cache -
Rails.cache.fetch: this method either get from the cache or from the backing data store and then sets it in the cache for the next time
Let’s look at what is happening with these methods so we can see how they help abstract away and handle many shared operations. We will see common patterns like:
- serialization (and deserialization)
- compression (and decompression)
- cache store API specifics
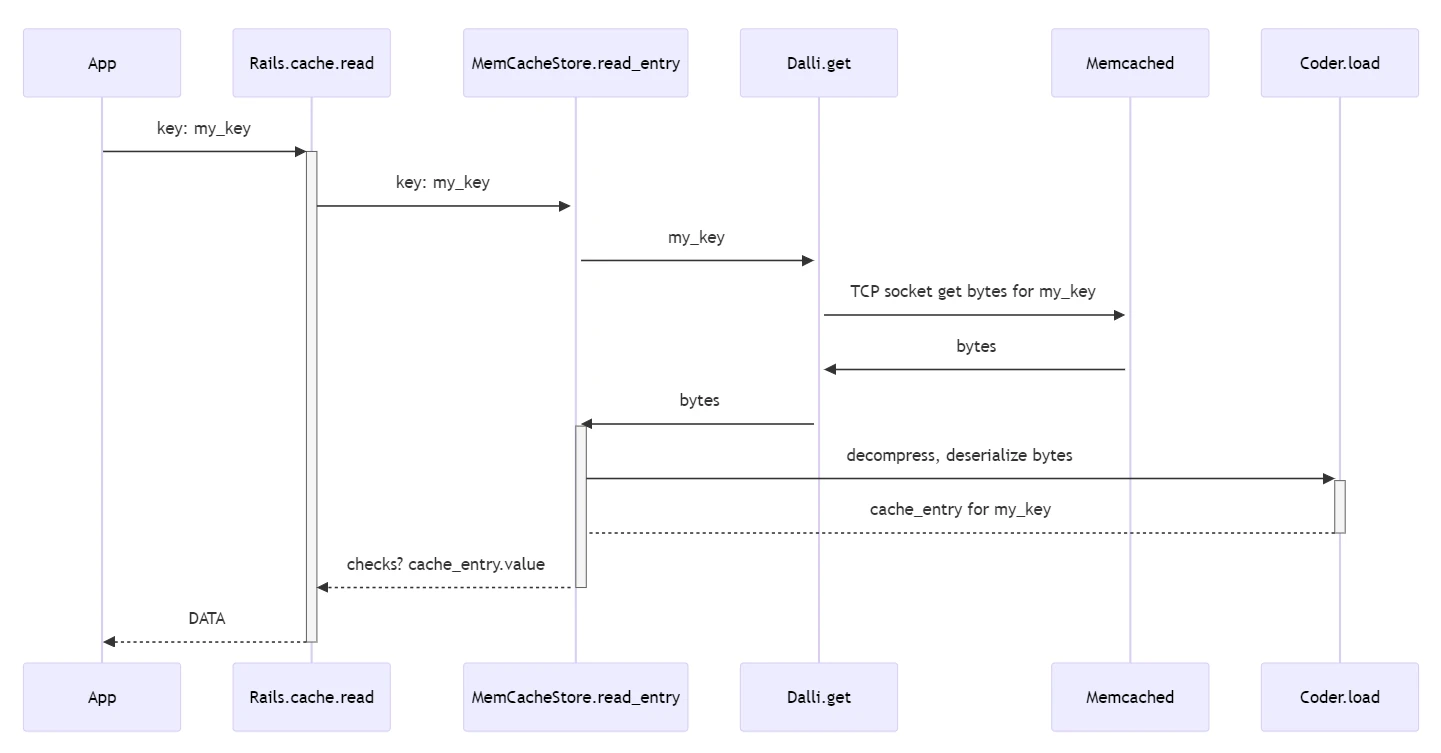
Rails.cache.read
When calling Rails.cache.read, the application code is trying to find some piece of data in the cache.
result = Rails.cache.read(key)
What does this do? It depends, but let’s assume we have the Rails MemCache Store configured as our cache store and a valid Memcached server, which does contain the data stored for the cache key.
-
ActiveSupport::Cache::Store.read
- normalize the key
- normalize cache key versions (supports recycling keys)
- instruments the cache call (for tracing, logging, testing, stats)
- set
entryequal to the response from the configured ActiveSupport::Cache::MemCacheStore.read_entry call- this method does two things
deserialize_entry(read_serialized_entry(key, **options), **options)-
read_serialized_entry: this will use the Cache store-specific way to get the serialized data out of the cache- for the MemCacheStore this means it will use the Dalli Memcached Client gem to request the data over a socket
-
deserialize_entry: is back in the base class and uses the coder to get the cache entry and metadata-
@coder.load(payload): this will first have the coder decompress the raw cache data if needed, then it will deserialize it
-
-
- checks meta data on the entry to handle things like cleaning up and not returning expired entries
- returns the cache
entry.valueback to the caller ofcache.read
- this method does two things
All the above can occur in less than 1ms for a remote network cache call when on a fast cloud regional deployment. It is a lot to take in, let’s diagram it.
Rails.cache.write
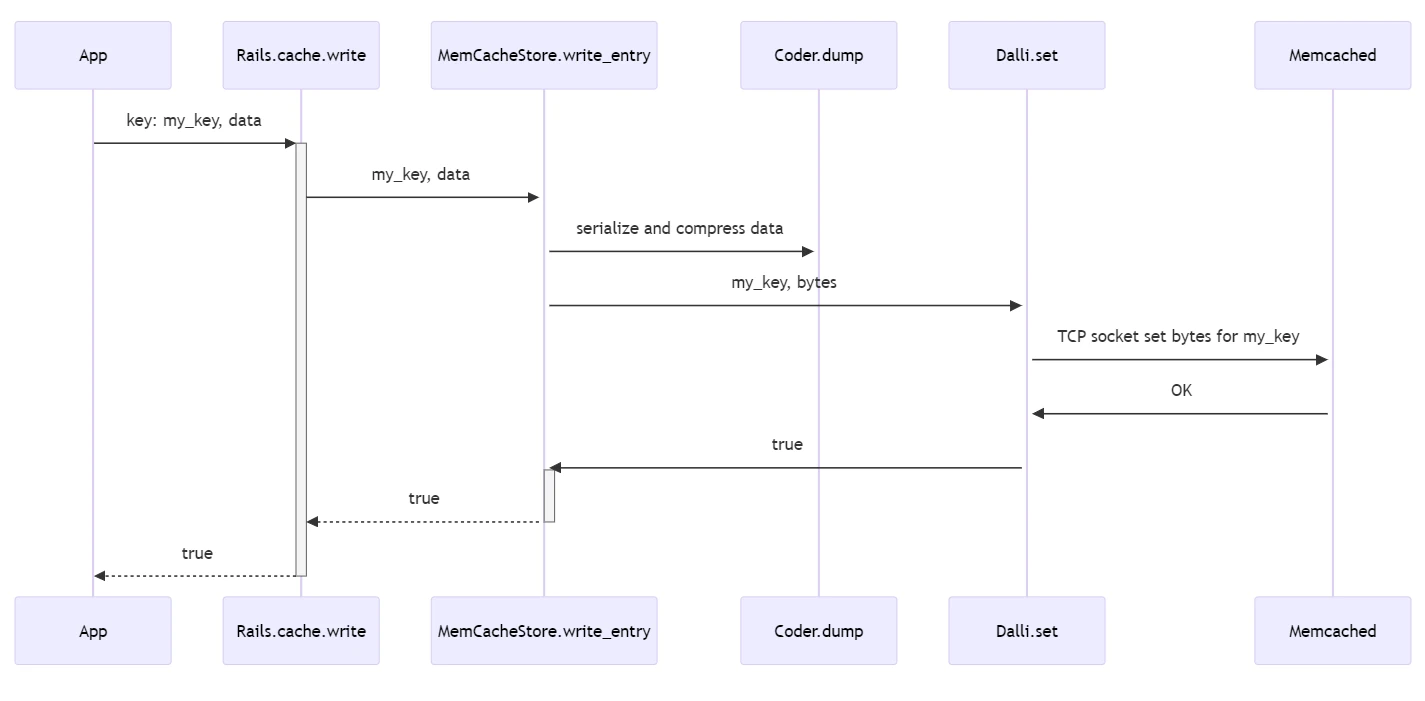
When calling Rails.cache.write the application code is trying to store some piece of data in the cache.
book = Book.first # some active record book object
Rails.cache.write(key, book, ttl: 3600)
What does this do? It depends, but let’s assume we have the Rails MemCache Store configured as our cache store and a valid Memcached server.
-
ActiveSupport::Cache::Store.write
- normalize the key
- normalize cache key versions (supports recycling keys)
- instruments the cache call (for tracing, logging, testing, stats)
- builds the CacheEntry object (meta data and value wrapper)
- calls ActiveSupport::Cache::MemCacheStore.write_entry to set the value
- this method does two things ` write_serialized_entry(key, serialize_entry(entry, **options), **options)`
-
serialize_entry: is back in the base class and uses the coder to serialize the data-
@coder.dump_compressed(payload): (or just dump if no compression needed) This will have coder serialize and then compress the data
-
-
write_serialized_entry: this will use the Cache store-specific way to set the serialized data to the cache- for the MemCacheStore this means it will use the Dalli Memcached Client gem to send the data over a socket
- returns true if set successfully
All the above can occur in less than 1ms for a remote network cache call when on a fast cloud regional deployment. It is a lot to take in, let’s diagram it.
Rails.cache.fetch
A very common pattern with caching is to try to get a piece of data from the cache, and if you can’t find it, get the data from another data store and save it to the cache so you will get it next time. Rails has the Rails.cache.fetch helper to simplify this.
Rails.cache.fetch(key, ttl: 3600) {
Book.first # some active record book object
}
It is easiest to think of fetch in terms of both the previous read and write. While it duplicates some of the underlying code, it does not always directly differ from those methods. Let’s break this down for the Memcache store in the case where there is a miss on the cache read.
-
Rails.cache.fetch
-
entry = read_entry: this does most of the same as read, and we will in this case, assume it was a miss and return nil save_block_result_to_cache(name, key, options, &block)- call the block, which in this case is
Book.first - then it is like cache.write with that value
-
While I very briefly covered fetch, it can do many other interesting things that help with the complexity and edge cases when using a cache, such as race conditions, nil handling, forcing updates, etc.
The most common cache call in most of the Rails apps I work in is Rails.cache.fetch it is extremely powerful for very basic caching.
Notes on Using Rails Cache
The purpose of this post was to get a bit deeper into the foundational concepts and steps related to caching with the active support cache store API. So, we can further explore some of the important concepts like serialization, compression, and specific cache store implementations. It is important to realize that for each different store type, Rails relies on a client; in this case, we talked about Dalli being the Memcached client, but if you use the Redis store, Rails will end up using the Redis gem. While Rails will default to using compression and serialization built into Ruby, other options (often better options) also rely on the gem ecosystem outside of Rails.
- In my example, I cached an active record object. The Rails caching guide rightly warns against this, as we get into serialization and versioning, we can cover solutions to problems with caching Active Record objects
- These examples should also make it clear that much is happening behind the scenes for such a simple API (can’t get much easier than
read('key")), it is important to understand the different pieces when wanting to optimize performance further when working on caching- for complex data structures, serialization can take longer than network calls
- for certain size data and data formats, avoiding compression can make sense
- knowing how caching breaks down into these steps can help when benchmarking and profiling caching approaches that work best for your data
We will dig in a bit more in a future post.